查询¶
Pony 提供了一种非常方便的方式,使用生成器表达式语法来查询数据库。Pony 允许程序员使用原生 Python 语法来操作存储在数据库中的对象,就好像它们存储在内存中一样。这使得开发变得更加容易。
可以使用 Python 生成器表达式或 lambda 表达式来编写查询。
使用 Python 生成器表达式¶
Pony 允许使用生成器表达式作为编写数据库查询的非常自然的方式。Pony 提供了 select() 函数,它接受 Python 生成器,将其转换为 SQL 并返回来自数据库的对象。转换过程在 StackOverflow 问题 中进行了描述。
以下是一个查询示例
query = select(c for c in Customer
if sum(o.total_price for o in c.orders) > 1000)
或者,使用 属性提升
query = select(c for c in Customer
if sum(c.orders.total_price) > 1000)
可以将 filter() 函数应用于查询
query2 = query.filter(lambda person: person.age > 18)
还可以根据另一个查询创建新的查询
query3 = select(customer.name for customer in query2
if customer.country == 'Canada')
select() 函数返回一个 Query 类的实例,然后可以调用 Query 对象的方法来获取结果,例如
customer_name = query3.first()
从查询中可以返回实体、属性或任意表达式的元组
select((c, sum(c.orders.total_price))
for c in Customer if sum(c.orders.total_price) > 1000)
使用 lambda 函数¶
可以使用 lambda 函数来编写查询,而不是使用生成器。
Customer.select(lambda c: sum(c.orders.price) > 1000)
从将查询转换为 SQL 的角度来看,使用生成器或 lambda 表达式没有区别。唯一的区别是,使用 lambda 表达式只能返回实体实例 - 无法返回特定实体属性列表或元组列表。
用于查询数据库的 Pony ORM 函数¶
有关详细信息,请参阅 API 参考中的 查询和函数 部分。
Pony 查询示例¶
为了演示 Pony 查询,让我们使用 Pony ORM 发行版中的示例。可以在交互模式下尝试这些查询,并查看生成的 SQL。为此,请以这种方式导入示例模块
>>> from pony.orm.examples.estore import *
此模块提供了一个简化的电子商务在线商店数据模型。以下是 数据模型的 ER 图
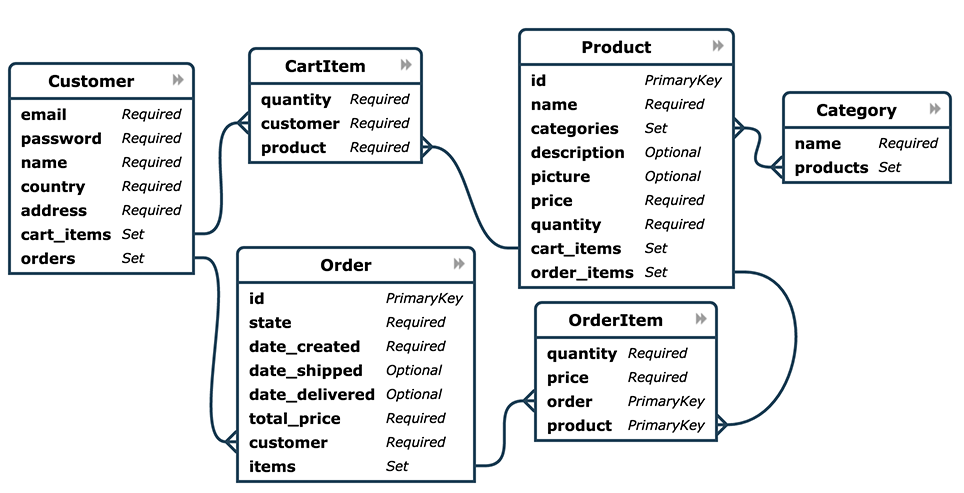
以下是实体定义
from decimal import Decimal
from datetime import datetime
from pony.converting import str2datetime
from pony.orm import *
db = Database()
class Customer(db.Entity):
email = Required(str, unique=True)
password = Required(str)
name = Required(str)
country = Required(str)
address = Required(str)
cart_items = Set('CartItem')
orders = Set('Order')
class Product(db.Entity):
id = PrimaryKey(int, auto=True)
name = Required(str)
categories = Set('Category')
description = Optional(str)
picture = Optional(buffer)
price = Required(Decimal)
quantity = Required(int)
cart_items = Set('CartItem')
order_items = Set('OrderItem')
class CartItem(db.Entity):
quantity = Required(int)
customer = Required(Customer)
product = Required(Product)
class OrderItem(db.Entity):
quantity = Required(int)
price = Required(Decimal)
order = Required('Order')
product = Required(Product)
PrimaryKey(order, product)
class Order(db.Entity):
id = PrimaryKey(int, auto=True)
state = Required(str)
date_created = Required(datetime)
date_shipped = Optional(datetime)
date_delivered = Optional(datetime)
total_price = Required(Decimal)
customer = Required(Customer)
items = Set(OrderItem)
class Category(db.Entity):
name = Required(str, unique=True)
products = Set(Product)
set_sql_debug(True)
db.bind('sqlite', 'estore.sqlite', create_db=True)
db.generate_mapping(create_tables=True)
导入此示例后,它将在文件 'estore.sqlite' 中创建 SQLite 数据库,并用一些测试数据填充它。下面可以看到一些查询示例
# All USA customers
Customer.select(lambda c: c.country == 'USA')
# The number of customers for each country
select((c.country, count(c)) for c in Customer)
# Max product price
max(p.price for p in Product)
# Max SSD price
max(p.price for p in Product
for cat in p.categories if cat.name == 'Solid State Drives')
# Three most expensive products
Product.select().order_by(desc(Product.price))[:3]
# Out of stock products
Product.select(lambda p: p.quantity == 0)
# Most popular product
Product.select().order_by(lambda p: desc(sum(p.order_items.quantity))).first()
# Products that have never been ordered
Product.select(lambda p: not p.order_items)
# Customers who made several orders
Customer.select(lambda c: count(c.orders) > 1)
# Three most valuable customers
Customer.select().order_by(lambda c: desc(sum(c.orders.total_price)))[:3]
# Customers whose orders were shipped
Customer.select(lambda c: SHIPPED in c.orders.state)
# Customers with no orders
Customer.select(lambda c: not c.orders)
# The same query with the LEFT JOIN instead of NOT EXISTS
left_join(c for c in Customer for o in c.orders if o is None)
# Customers which ordered several different tablets
select(c for c in Customer
for p in c.orders.items.product
if 'Tablets' in p.categories.name and count(p) > 1)
可以在 pony.orm.examples.estore 模块中找到更多查询。
查询对象方法¶
有关详细信息,请参阅 API 参考中的 查询结果 部分。
在查询中使用日期和时间¶
可以在查询中对 datetime 和 timedelta 进行算术运算。
如果表达式可以在 Python 中计算,Pony 会将计算结果作为参数传递到查询中
select(o for o in Order if o.date_created >= datetime.now() - timedelta(days=3))[:]
SELECT "o"."id", "o"."state", "o"."date_created", "o"."date_shipped",
"o"."date_delivered", "o"."total_price", "o"."customer"
FROM "Order" "o"
WHERE "o"."date_created" >= ?
如果需要对属性执行操作,则无法事先计算它。这就是为什么这种表达式将被转换为 SQL 的原因
select(o for o in Order if o.date_created + timedelta(days=3) >= datetime.now())[:]
SELECT "o"."id", "o"."state", "o"."date_created", "o"."date_shipped",
"o"."date_delivered", "o"."total_price", "o"."customer"
FROM "Order" "o"
WHERE datetime("o"."date_created", '+3 days') >= ?
Pony 生成的 SQL 将根据数据库而有所不同。以上是 SQLite 的示例。以下是相同的查询,转换为 PostgreSQL
SELECT "o"."id", "o"."state", "o"."date_created", "o"."date_shipped",
"o"."date_delivered", "o"."total_price", "o"."customer"
FROM "order" "o"
WHERE ("o"."date_created" + INTERVAL '72:0:0' DAY TO SECOND) >= %(p1)s
如果需要使用 SQL 函数,可以使用 raw_sql() 函数来包含此 SQL 片段
select(m for m in DBVoteMessage if m.date >= raw_sql("NOW() - '1 minute'::INTERVAL"))
使用 Pony,可以使用 datetime 属性,例如 month、hour 等。根据数据库的不同,它将被转换为不同的 SQL,这将提取此属性的值。在此示例中,获取 month 属性
select(o for o in Order if o.date_created.month == 12)
以下是 SQLite 转换结果
SELECT "o"."id", "o"."state", "o"."date_created", "o"."date_shipped",
"o"."date_delivered", "o"."total_price", "o"."customer"
FROM "Order" "o"
WHERE cast(substr("o"."date_created", 6, 2) as integer) = 12
以下是 PostgreSQL 的结果
SELECT "o"."id", "o"."state", "o"."date_created", "o"."date_shipped",
"o"."date_delivered", "o"."total_price", "o"."customer"
FROM "order" "o"
WHERE EXTRACT(MONTH FROM "o"."date_created") = 12
自动 DISTINCT¶
Pony 尝试通过在必要时自动添加 DISTINCT SQL 关键字来避免查询结果中的重复项,因为有用的包含重复项的查询非常少见。当有人想要检索符合特定条件的对象时,他们通常不希望同一个对象被返回多次。此外,避免重复项使查询结果更具可预测性:不需要从查询结果中过滤掉重复项。
Pony 仅在可能存在潜在重复项时才添加 DISCTINCT 关键字。让我们考虑几个示例。
检索符合条件的对象
Person.select(lambda p: p.age > 20 and p.name == 'John')
在此示例中,查询不会返回重复项,因为结果包含 Person 的主键列。由于此处不可能出现重复项,因此不需要 DISTINCT 关键字,Pony 不会添加它
SELECT "p"."id", "p"."name", "p"."age"
FROM "Person" "p"
WHERE "p"."age" > 20
AND "p"."name" = 'John'
检索对象属性
select(p.name for p in Person)
此查询的结果不是返回对象,而是返回其属性。此查询结果可能包含重复项,因此 Pony 会将 DISTINCT 添加到此查询中
SELECT DISTINCT "p"."name"
FROM "Person" "p"
此类查询的结果通常用于下拉列表,其中不希望出现重复项。很难想出一个需要在此处包含重复项的实际用例。
如果需要计算具有相同名称的人数,最好使用聚合查询
select((p.name, count(p)) for p in Person)
但是,如果绝对有必要获取所有人的姓名,包括重复项,可以使用 Query.without_distinct() 方法
select(p.name for p in Person).without_distinct()
使用联接检索对象
select(p for p in Person for c in p.cars if c.make in ("Toyota", "Honda"))
此查询可能包含重复项,因此 Pony 使用 DISTINCT 来消除它们
SELECT DISTINCT "p"."id", "p"."name", "p"."age"
FROM "Person" "p", "Car" "c"
WHERE "c"."make" IN ('Toyota', 'Honda')
AND "p"."id" = "c"."owner"
不使用 DISTINCT,重复项是可能的,因为查询使用了两个表(Person 和 Car),但在 SELECT 部分中只使用了一个表。上面的查询只返回人(而不是他们的汽车),因此通常不希望在结果中多次获取同一个人。我们认为,没有重复项,结果看起来更直观。
但是,如果出于某种原因不需要排除重复项,始终可以将 without_distinct() 添加到查询中
select(p for p in Person for c in p.cars
if c.make in ("Toyota", "Honda")).without_distinct()
如果查询结果包含每个人拥有的汽车,用户可能希望看到 Person 对象的重复项。在这种情况下,Pony 查询将有所不同
select((p, c) for p in Person for c in p.cars if c.make in ("Toyota", "Honda"))
在这种情况下,Pony 不会将 DISTINCT 关键字添加到 SQL 查询中。
总结
原则“所有查询默认情况下不返回重复项”易于理解,不会导致意外。
这种行为是大多数用户在大多数情况下想要的。
Pony 在查询不应包含重复项时不会添加 DISTINCT。
查询方法
without_distinct()可用于强制 Pony 不消除重复项。
可以在查询中使用的函数¶
以下是可以在生成器查询中使用的函数列表
abs()
示例
select(avg(c.orders.total_price) for c in Customer)
SELECT AVG("order-1"."total_price")
FROM "Customer" "c"
LEFT JOIN "Order" "order-1"
ON "c"."id" = "order-1"."customer"
select(o for o in Order if o.customer in
select(c for c in Customer if c.name.startswith('A')))[:]
SELECT "o"."id", "o"."state", "o"."date_created", "o"."date_shipped",
"o"."date_delivered", "o"."total_price", "o"."customer"
FROM "Order" "o"
WHERE "o"."customer" IN (
SELECT "c"."id"
FROM "Customer" "c"
WHERE "c"."name" LIKE 'A%'
)
使用 getattr()¶
getattr() 是一个内置的 Python 函数,可用于获取属性值。
示例
attr_name = 'name'
param_value = 'John'
select(c for c in Customer if getattr(c, attr_name) == param_value)
使用原始 SQL¶
Pony 允许在查询中使用原始 SQL。可以使用两种方法来使用原始 SQL
使用
raw_sql()函数,以便仅使用原始 SQL 来编写生成器或 lambda 查询的一部分。使用
Entity.select_by_sql()或Entity.get_by_sql()方法编写完整的 SQL 查询。
使用 raw_sql() 函数¶
让我们探索使用 raw_sql() 函数的示例。以下是我们将用于示例的模式和初始数据
from datetime import date
from pony.orm import *
db = Database('sqlite', ':memory:')
class Person(db.Entity):
id = PrimaryKey(int)
name = Required(str)
age = Required(int)
dob = Required(date)
db.generate_mapping(create_tables=True)
with db_session:
Person(id=1, name='John', age=30, dob=date(1986, 1, 1))
Person(id=2, name='Mike', age=32, dob=date(1984, 5, 20))
Person(id=3, name='Mary', age=20, dob=date(1996, 2, 15))
raw_sql() 结果可以被视为逻辑表达式
select(p for p in Person if raw_sql('abs("p"."age") > 25'))
raw_sql() 结果可用于比较
q = Person.select(lambda x: raw_sql('abs("x"."age")') > 25)
print(q.get_sql())
SELECT "x"."id", "x"."name", "x"."age", "x"."dob"
FROM "Person" "x"
WHERE abs("x"."age") > 25
此外,在上面的示例中,我们在 lambda 查询中使用了 raw_sql() 并打印出生成的 SQL。如您所见,原始 SQL 部分成为整个查询的一部分。
raw_sql() 可以接受 $parameters
x = 25
select(p for p in Person if raw_sql('abs("p"."age") > $x'))
可以动态更改 raw_sql() 函数的内容,并在其中使用参数
x = 1
s = 'p.id > $x'
select(p for p in Person if raw_sql(s))
使用动态原始 SQL 内容的另一种方法
x = 1
cond = raw_sql('p.id > $x')
select(p for p in Person if cond)
可以在原始 SQL 查询中使用各种类型
x = date(1990, 1, 1)
select(p for p in Person if raw_sql('p.dob < $x'))
原始 SQL 部分中的参数可以组合在一起
x = 10
y = 15
select(p for p in Person if raw_sql('p.age > $(x + y)'))
甚至可以在其中调用 Python 函数
select(p for p in Person if raw_sql('p.dob < $date.today()'))
raw_sql() 函数不仅可以在条件部分使用,还可以在返回查询结果的部分使用
names = select(raw_sql('UPPER(p.name)') for p in Person)[:]
print(names)
['JOHN', 'MIKE', 'MARY']
但是,当您使用 raw_sql() 函数返回数据时,您可能需要指定结果的类型,因为 Pony 不知道结果类型是什么。
dates = select(raw_sql('(p.dob)') for p in Person)[:]
print(dates)
['1985-01-01', '1983-05-20', '1995-02-15']
如果您想将结果作为日期列表获取,您需要指定 result_type。
dates = select(raw_sql('(p.dob)', result_type=date) for p in Person)[:]
print(dates)
[datetime.date(1986, 1, 1), datetime.date(1984, 5, 20), datetime.date(1996, 2, 15)]
raw_sql() 函数可以在 Query.filter() 中使用。
x = 25
select(p for p in Person).filter(lambda p: p.age > raw_sql('$x'))
它可以在 Query.filter() 中使用,无需 lambda。在这种情况下,您必须使用实体名称的首字母小写作为别名。
x = 25
Person.select().filter(raw_sql('p.age > $x'))
您可以在单个查询中使用多个 raw_sql() 表达式。
x = '123'
y = 'John'
Person.select(lambda p: raw_sql("UPPER(p.name) || $x")
== raw_sql("UPPER($y || '123')"))
相同的参数名称可以在不同的类型和值下使用多次。
x = 10
y = 31
q = select(p for p in Person if p.age > x and p.age < raw_sql('$y'))
x = date(1980, 1, 1)
y = 'j'
q = q.filter(lambda p: p.dob > x and p.name.startswith(raw_sql('UPPER($y)')))
persons = q[:]
您可以在 Query.order_by() 部分使用 raw_sql()。
x = 9
Person.select().order_by(lambda p: raw_sql('SUBSTR(p.dob, $x)'))
或者,如果您使用与之前过滤器中相同的别名,则无需使用 lambda。在这种情况下,我们使用默认别名 - 实体名称的首字母。
x = 9
Person.select().order_by(raw_sql('SUBSTR(p.dob, $x)'))
使用 select_by_sql() 和 get_by_sql() 方法¶
尽管 Pony 可以将几乎所有用 Python 编写的条件转换为 SQL,但有时需要使用原始 SQL,例如 - 为了调用存储过程或使用特定数据库系统的方言功能。在这种情况下,Pony 允许用户在原始 SQL 中编写查询,方法是将其放在函数 Entity.select_by_sql() 或 Entity.get_by_sql() 中作为字符串。
Product.select_by_sql("SELECT * FROM Products")
与方法 Entity.select() 不同,方法 Entity.select_by_sql() 不返回 Query 对象,而是返回实体实例列表。
参数使用以下语法传递:“$name_variable” 或 “$(expression in Python)”。例如
x = 1000
y = 500
Product.select_by_sql("SELECT * FROM Product WHERE price > $x OR price = $(y * 2)")
当 Pony 在原始 SQL 查询中遇到参数时,它会从当前帧(从全局变量和局部变量)或从可以作为参数传递的字典中获取变量值。
Product.select_by_sql("SELECT * FROM Product WHERE price > $x OR price = $(y * 2)",
globals={'x': 100}, locals={'y': 200})
在 $ 符号后指定的变量和更复杂的表达式将自动计算并作为参数传递到查询中,这使得 SQL 注入成为不可能。Pony 自动将查询字符串中的 $x 替换为“?”、“%S”或其他 paramstyle,用于您的数据库。
如果您需要在查询中使用 $ 符号(例如,在系统表名称中),您必须连续写两个 $ 符号:$$。